OpenAI聊天机器人如此出色,甚至可以欺骗人类,即使它是错误的 - 彭博社
Dina Bass
自从OpenAI推出了ChatGPT,一个生成句子的聊天机器人,这些句子几乎与实际由人类撰写的散文相似,社交媒体上一直充斥着用户尝试使用这项技术进行有趣、低风险的用途。人们要求这个机器人创建鸡尾酒配方,创作歌词,并编写《格林纳达的孤岛》剧本,在这个剧本中,演员们应对新冠疫情。ChatGPT避免了一些过去聊天机器人的缺陷,比如种族主义或仇恨言论,对于这项技术的激动之情是可以感受到的。
ChatGPT擅长提供流畅、权威的答案,并能够在一个连贯的线程中回答额外的相关问题,这证明了人工智能已经取得了多大的进步。但这也引发了一系列问题,关于读者如何能够区分机器人的内容和真实的人类撰写的语言之间的区别。这是因为ChatGPT的文本可以达到某种程度的“真实感”,正如喜剧演员史蒂芬·科尔伯特曾经称之为“真实性” — 即使事实并非如此,它看起来和感觉上却是真实的。这个工具上周发布。到周一,面向计算机程序员的问答网站Stack Overflow暂时禁止了由ChatGPT生成的答案,管理员表示他们看到了成千上万这样的帖子 — 而且它们经常包含不准确的信息,使其对网站造成“实质性的伤害”。即使答案是准确的,这个机器人生成的关于历史或科学的材料也足够引发关于它是否可以用来作弊考试、论文或工作申请的争论。无论是否属实,ChatGPT的答案都是人类言论的近似回声,是真实事物的复制品,这加强了OpenAI可能必须想出一种方法来标记这样的内容为软件生成而非人类创作的论点。
普林斯顿大学计算机科学教授阿尔温德·纳拉亚南(Arvind Narayanan)在发布当天对聊天机器人进行了基本信息安全问题测试。他的结论:除非你已经知道正确答案,否则你无法判断答案是否错误。
“我没有看到任何证据表明ChatGPT如此具有说服力,以至于能够说服专家,”他在一次采访中说道。“对于非专家来说,他们可能会觉得ChatGPT非常可信和权威。”他还表示,对于那些要求背诵事实而非分析或批判性思维的老师来说,这也是一个问题。聊天机器人在第一部分表现得相当不错,但通常在后者上表现不佳。
ChatGPT是OpenAI最新的语言人工智能技术,OpenAI是一家人工智能研究机构,成立于2015年,创始人包括埃隆·马斯克(Elon Musk)、现任首席执行官和企业家萨姆·奥尔特曼(Sam Altman)以及首席科学家伊利亚·苏茨克维尔(Ilya Sutskever)。马斯克于2019年结束了他的参与,OpenAI现在得到微软公司的大力资助。该公司专注于几个版本的GPT,一种所谓的大型语言模型,它扫描互联网上的大量内容,并用它来预测如何生成文本。ChatGPT是一个经过“训练”来回答问题的迭代版本。
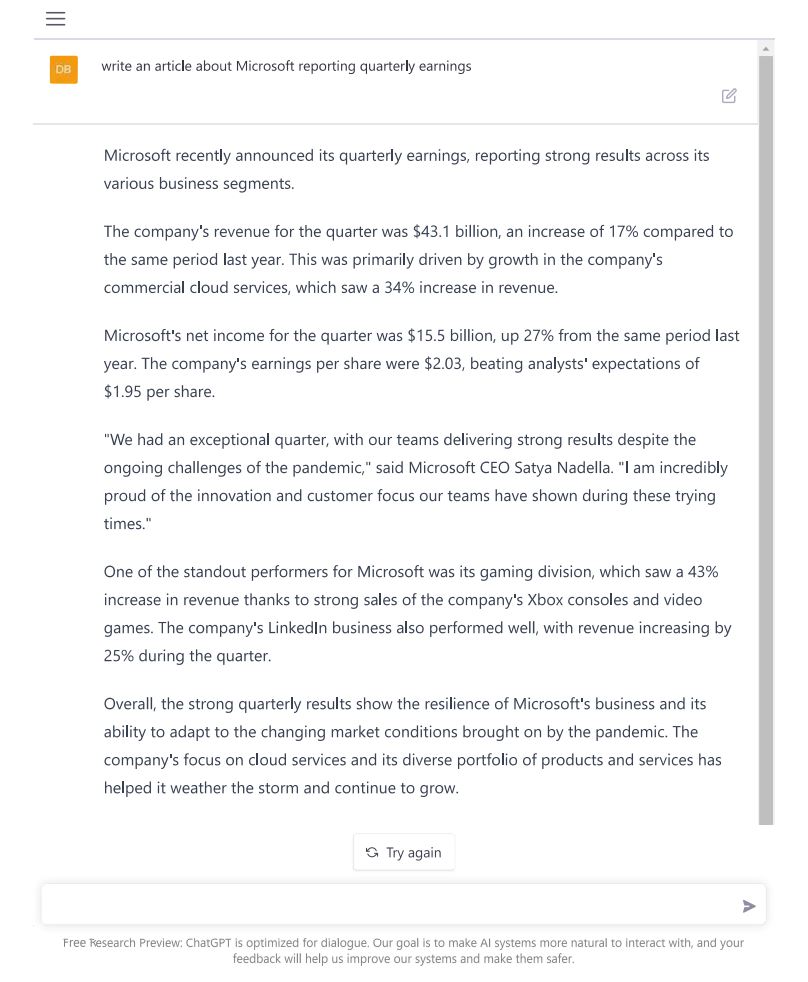
使用这个人工智能工具来写一个基本的新闻故事展示了它的优势以及潜在的缺点。要求写一篇关于微软季度收益的文章,这个机器人产生了一个可信的复制品,看起来像是关于2021年微软财务业绩的一篇文章。文章谈到了收入和利润的增长,归功于强劲的云计算软件和视频游戏销售。ChatGPT没有出现会让人怀疑它是机器人写的的明显错误。数字是错误的,但大致在范围内。这个机器人通过添加一句来自微软CEO萨蒂亚·纳德拉(Satya Nadella)的虚假引语增强了其可信度,其中存在一个令人担忧的问题。这条评论赞扬了微软在疫情期间的出色执行,甚至这位微软记者都不得不核实它是否真实。事实上,这完全是虚构的。正如微软人工智能伦理副总裁莎拉·伯德(Sarah Bird)在采访中在今年早些时候解释的那样,像GPT这样的语言模型已经学会了人类经常用引语来支持论点的行为,因此软件模仿了这种行为,但缺乏对伦理和归因的人类理解。软件会虚构引语,或者说话者,或者两者都会虚构。
对ChatGPT的热烈接待与最近另一个备受关注的语言模型展示形成鲜明对比 —— Meta Platforms Inc.的Galactica,该模型摄入了大量科学论文和教科书,并应该利用这些“学习”来输出科学真相。用户发现这个机器人在科学术语中穿插着不准确和偏见,导致Meta、Facebook的母公司,停止了这个项目。“我不确定有人怎么会认为那是个好主意,”Narayanan说。“在科学中,准确性就是全部。”
OpenAI明确表示,其聊天机器人不“能够产生类似人类的言论”,根据服务上的免责声明。“像ChatGPT这样的语言模型被设计成模拟人类语言模式,并生成类似人类回应的回答,但它们没有产生类似人类言论的能力。”
ChatGPT还被设计成避免一些更明显的陷阱,并更好地考虑到可能出错的可能性。该软件仅在去年的数据上进行了训练。例如,问及今年的中期选举,该软件会承认自己的局限性。“很抱歉,但我是由OpenAI训练的大型语言模型,没有任何关于当前事件或最近选举结果的信息,”它说。“我的训练数据仅限于2021年,我没有能力浏览互联网或获取任何更新的信息。我能帮你做些什么吗?”
 摄影师:OpenAIOpenAI提供的示例显示,ChatGPT拒绝回答有关欺凌或提供暴力内容的问题。它没有回答我在2021年1月6日美国国会大厦暴动事件上提出的问题,有时承认自己犯了错误。OpenAI表示,他们发布ChatGPT作为“研究预览”,以便从实际使用中获得反馈,这被视为制定安全系统的关键方式。
摄影师:OpenAIOpenAI提供的示例显示,ChatGPT拒绝回答有关欺凌或提供暴力内容的问题。它没有回答我在2021年1月6日美国国会大厦暴动事件上提出的问题,有时承认自己犯了错误。OpenAI表示,他们发布ChatGPT作为“研究预览”,以便从实际使用中获得反馈,这被视为制定安全系统的关键方式。
目前,它有一些严重错误。纽约大学荣誉退休教授Gary Marcus一直在Twitter上收集和分享示例,包括ChatGPT关于从旧金山骑自行车到毛伊岛的建议。加州大学博士生Rong-Ching Chang让这个机器人谈论了天安门广场抗议活动中的食人行为。这就是为什么一些人工智能专家担心,一些科技高管和用户将这项技术视为取代互联网搜索的一种方式,尤其是因为ChatGPT没有展示其工作过程或列出信息来源。
“如果你得到一个无法追溯的答案,无法问到‘这是从哪里来的?代表了什么观点?这个信息的来源是什么?’,那么你将极易受到虚构的信息或者反映数据集中最糟糕偏见的影响,”华盛顿大学语言学教授、一篇今年早些时候发表的论文的作者Emily Bender说。该论文展示了语言人工智能聊天机器人提出的改进网络搜索的担忧。这篇论文主要是针对谷歌提出的想法。
“这种技术的杀手级应用是在你不需要任何真实信息的情况下。” Bender说。“没有人可以根据它做出任何决定。”
这种软件也可以用于发起“人造草根”运动 — 让一个观点看起来来自大量的草根评论者,但实际上是来自一个中央管理的操作。
随着人工智能系统在模仿人类方面变得更加优秀,关于如何判断某些内容 — 一张图片,一篇文章 — 是否是根据少量人类指令创建的程序所生成的,以及谁有责任确保读者或观众知道内容的来源,这类问题将会越来越多。2018年,当谷歌发布了Duplex,一种模拟人类语音打电话给公司代表用户的人工智能时,由于有人抱怨它具有欺骗性,最终不得不标明这些电话来自机器人。
OpenAI表示他们已经探索了这个想法 — 例如,他们的DALL-E系统可以根据文本提示生成图片,并在图片上放置一个标记,说明这些图片是由人工智能创建的 — 该公司正在继续研究有关披露由其GPT等工具创建的文本来源的技术。OpenAI的政策还规定,分享这类内容的用户应清楚地指出这是由机器生成的。
“一般来说,当有一个工具可能被滥用但也有很多积极用途时,我们会把责任放在工具的使用者身上,”Narayanan说。“但这些都是非常强大的工具,生产它们的公司资源充足。因此,也许他们需要承担一部分道德责任。”