Breakingviews: 人工智能将踏上数据之旅 | 路透社
Karen Kwok
 “Desdemona”,一台由人工智能驱动的机器人,站在舞台上,回答来自访客的问题,地点是2023年9月1日在德国柏林举行的IFA国际消费电子展。路透社/利西·尼斯纳摄
“Desdemona”,一台由人工智能驱动的机器人,站在舞台上,回答来自访客的问题,地点是2023年9月1日在德国柏林举行的IFA国际消费电子展。路透社/利西·尼斯纳摄
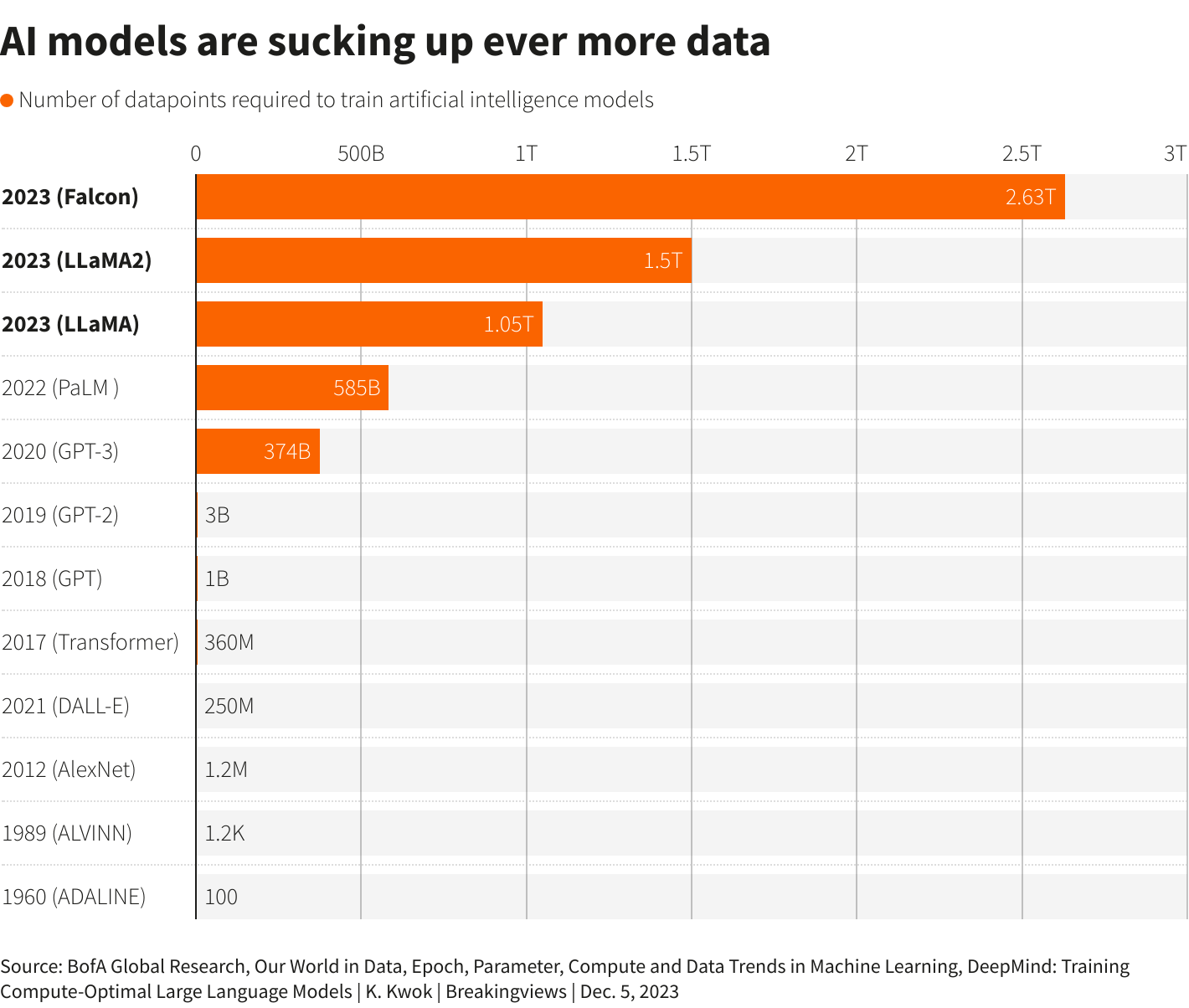
伦敦,12月22日(路透社Breakingviews)-人工智能竞赛正在变成一场数据争夺战。最尖端的人工智能模型已经能够在美国律师资格考试中取得高分,并且能够写出类似人类的文本。为了不断提高它们的能力,软件需要在更复杂的信息上进行自我训练,比如图片和科学论文。但这些数据更难获取,成本更高。
人工智能软件的复杂程度在很大程度上取决于它所训练的数据集的质量。社交媒体帖子在互联网上很容易找到,但可能会反映出偏见或成见,而图片往往是模糊的。使用这些数据可能会导致种族主义和厌女症的输出,就像微软(MSFT.O)经历的当它使用Twitter帖子训练一个人工智能模型时。
这就是为什么人工智能公司正在寻找更可靠的来源,比如科学论文和专业作者撰写的书籍。这些更难找到。Epoch的研究人员将数据分为高质量和低质量,估计互联网上可能有多达17万亿高质量词汇,而低质量词汇可能多达71万亿万亿。如果人工智能模型以当前的速度继续吞噬信息,它们可能会在2026年之前耗尽优质数据。
 路透社图形
路透社图形
开发人员的一个选择是使用人工智能为特定模型生成新数据。一些项目已经在使用所谓的合成内容,通常是从数据生成服务(如Mostly AI)获取的。美国运通 创建 这样的数据来帮助其检测不寻常的欺诈模式,而Alphabet的 (GOOGL.O) Waymo使用虚构的场景来帮助训练其自动驾驶软件。研究机构Gartner预计,2024年60%的人工智能数据将是合成的,而2021年仅为1%。
然而,人工智能模型仍然渴望大型出版商和离线存储库持有的真实世界信息。这可能成为像RELX (REL.L)这样的集团的意外收获,它拥有《柳叶刀》和LexisNexis法律数据库。该公司的股价在去年上涨了30%以上,价值超过700亿美元。News Corp (NWSA.O),出版《华尔街日报》和《泰晤士报》,正在与人工智能开发人员 谈判 内容交易,该公司表示这将带来“可观的收入”。
这样的交易将成为人工智能公司的额外成本,这些公司已经花费相当于其收入的15%来整理和清理数据,风险投资公司Andreessen Horowitz 估计。版税支付将侵蚀利润率,而昂贵的计算能力和不断上升的云存储成本也使利润率变薄。但像OpenAI这样的公司,创造了ChatGPT聊天机器人,别无选择。Warner Music Group、Getty Images和许多其他创作者正在 起诉 人工智能公司未经授权使用其内容。无论如何,人工智能公司都将不得不为其数据付费。
关注 @karenkkwok on X
- 这是2024年Breakingviews的预测。要查看更多我们的预测,请点击 这里。
背景新闻
Axel Springer正在与OpenAI合作,根据人工智能公司的ChatGPT聊天机器人提出的问题,提供新闻发布商内容的摘要,这两家公司于12月13日宣布。
Axel Springer将收到一次性付款,用于训练AI技术的历史内容,并收到年度许可费,让OpenAI可以访问更新的信息。据《金融时报》援引一位知情人士的话报道,这笔年度费用可能达到“八位数”。
由Peter Thal Larsen和Sharon Lam编辑
所表达的观点属于作者个人。它们不代表路透社新闻的观点,根据信任原则,路透社致力于诚信、独立和无偏见。