想了解人工智能术语吗?学习基础知识,从自然语言处理到神经网络 - WSJ
Steven Rosenbush, Isabelle Bousquette and Belle Lin
一系列令人困惑的新术语伴随着人工智能的崛起而出现,这项技术旨在模仿人类思维。从生成式人工智能到机器学习、神经网络和幻觉,我们获得了全新的词汇。以下是一些AI背后最重要概念的指南,以帮助揭秘我们这一生中最具影响力的技术革命:
**算法:**如今的算法通常是计算机要遵循的一组指令。用于搜索和排序数据的算法是计算机算法的例子,它们用于检索信息并按特定顺序排列。它们可以由单词、数字或代码和符号组成,只要它们能够详细说明完成任务的有限步骤。但算法的根源可以追溯到古代,至少可以追溯到巴比伦时代的粘土板。至今仍在使用的欧几里得除法算法,甚至刷牙也可以被简化为一个算法,尽管考虑到这种日常仪式中涉及的精细动作的协调,这是一个非常复杂的算法。今天仍在使用,而刷牙甚至可以被简化为一个算法,尽管考虑到这种日常仪式中涉及的精细动作的协调,这是一个非常复杂的算法。
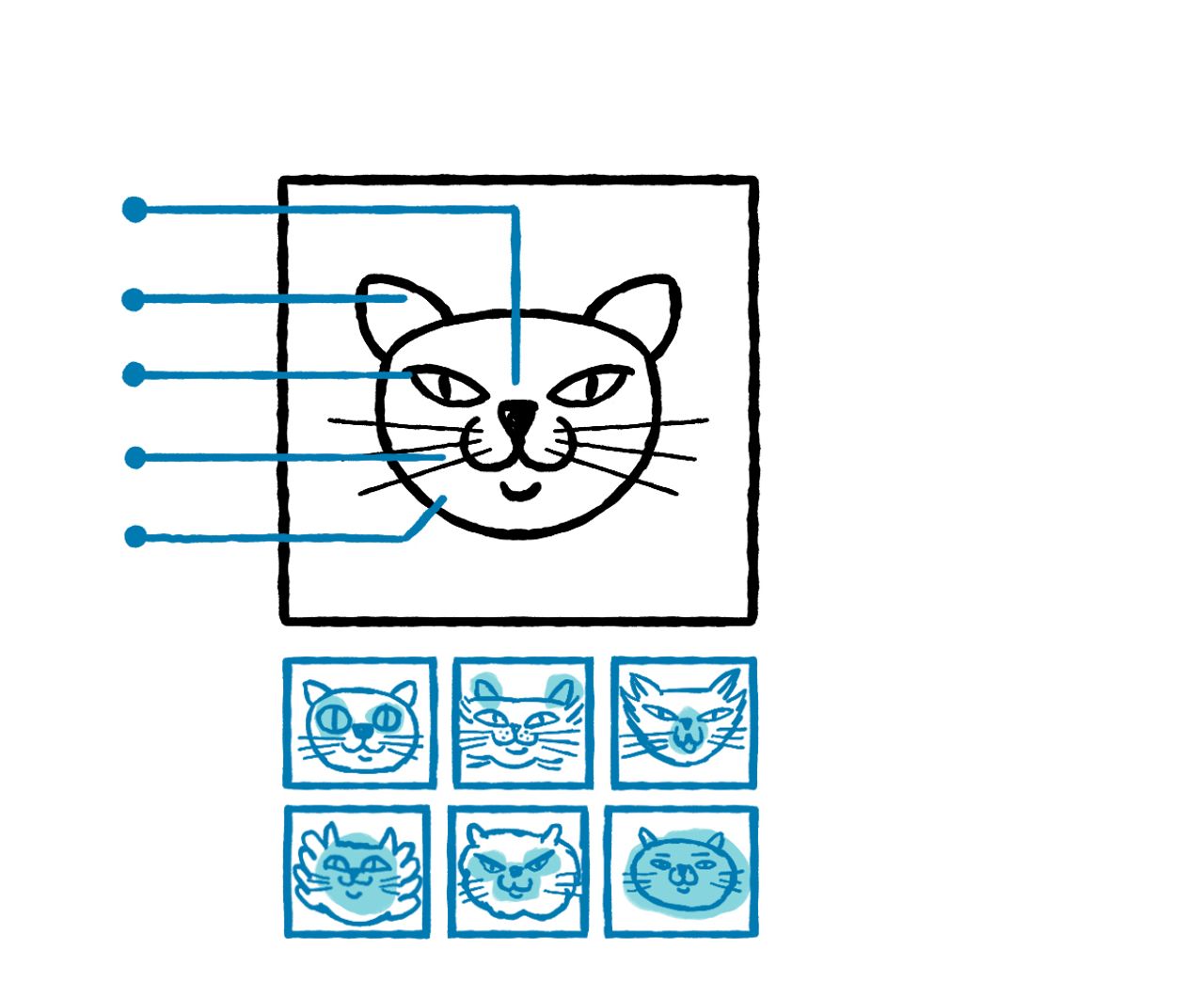
你可以给一个机器学习系统提供来自网络的数百万张动物图片,每张都标记为猫或狗。这个提供信息的过程被称为“训练”。在不知道动物的其他任何信息的情况下,系统可以识别图片中的统计模式,然后利用这些模式来识别和分类新的猫和狗的例子。
虽然机器学习系统非常擅长识别数据中的模式,但在任务需要长时间的推理链或复杂规划时,它们的效果就不那么好了。
**自然语言处理:**一种机器学习形式,可以解释和回应人类语言。它驱动着苹果的Siri和亚马逊的Alexa。今天的许多自然语言处理技术根据它们满足目标的概率选择一系列单词,比如总结、问答或翻译,DeepMind的员工研究科学家丹尼尔·曼科维茨说。
它可以根据周围文本的上下文判断“俱乐部”这个词可能是指三明治、高尔夫游戏还是夜生活。这个领域可以追溯到20世纪50年代和60年代,当时帮助计算机分析和理解语言的过程需要科学家自己编写规则。如今,计算机被训练成自己进行这些语言关联。
**神经网络:**机器学习中的一种技术,模仿神经元在人脑中的工作方式。在大脑中,神经元可以发送和接收信号,驱动思维和情感。在人工智能中,一组人工神经元或节点类似地相互发送和接收信息。人工神经元本质上是一行代码,作为与其他人工神经元形成神经网络的连接点。
与旧形式的机器学习不同,它们不断地在新数据上进行训练,并从错误中学习。例如,Pinterest 使用神经网络来通过处理关于用户的大量数据,如搜索、他们关注的画板以及点击和保存的图钉,来找到能吸引消费者注意的图片和广告。同时,这些网络还会查看用户的广告数据,比如什么内容能让他们点击广告,以了解他们的兴趣并提供更相关的内容。
深度学习:一种采用神经网络并不断学习的人工智能形式。深度学习中的“深度”指的是网络中的多个人工神经元层。与更擅长解决较小问题的神经网络相比,深度学习算法由于其相互连接的节点层而能够进行更复杂的处理。尽管它们受到人脑解剖学的启发,但是,如牛津大学博士候选人大卫·沃森在2019年的一篇论文中所述,与实际人脑的表现相比,神经网络是脆弱的、低效的和目光短浅的。自从多伦多大学的三名研究人员在2012年发表了一篇具有里程碑意义的论文以来,这种方法就变得异常受欢迎。

LLM源自谷歌于2017年开发的“transformer”模型,使得用大量数据训练模型更加便宜和高效。OpenAI于2018年发布的第一个GPT模型是基于谷歌的transformer工作构建的。(GPT代表生成预训练变换器。)被称为多模态语言模型的LLM可以在不同的模态下运行,比如语言、图像和音频。
对生成式人工智能的兴趣在去年11月爆发,ChatGPT的发布使得通过以日常语言输入问题或提示与OpenAI的基础技术进行交互变得容易。同样,OpenAI的Dall-E 2可以创建逼真的图像。
这些模型不仅在互联网上进行训练,还在更专门的数据集上进行训练,以找到数据序列中的长程模式,使得AI软件能够在写作或创作时表达出合适的下一个词或段落。

**幻觉:**指基础模型产生的回应不基于事实或现实,但被呈现为如此。幻觉不同于偏见,偏见是另一个问题,当训练数据存在偏见影响了语言生成模型的输出时会发生。幻觉是生成式人工智能的主要缺陷之一,促使许多专家呼吁对语言生成模型及其输出进行人类监督。
这个术语在2015年OpenAI创始成员Andrej Karpathy的一篇博客文章之后开始受到认可,他在文章中写道模型如何“产生幻觉”文本响应,比如编造合理的数学证明。
**人工通用智能:**一种假设的人工智能形式,其中机器可以像人类一样学习和思考。虽然人工智能界对AGI将包含什么尚未达成广泛共识,但研究公司IDC的技术分析师Ritu Jyoti表示,它需要自我意识和意识,以便它能够解决问题,适应其环境并执行更广泛的任务。
包括谷歌DeepMind在内的公司正在努力开发某种形式的AGI。DeepMind表示,其AlphaGo程序观看了大量的业余比赛,这帮助它理解了合理的人类下棋方式。然后它与不同版本的自己进行了数千次对弈,每次都从错误中学习。
随着时间的推移,AlphaGo变得越来越擅长学习和决策——这个过程被称为强化学习。DeepMind表示,其MuZero程序后来掌握了围棋、国际象棋、将棋和Atari,而无需告知规则,这展示了其在未知环境中规划获胜策略的能力。这一进展可能被一些人视为通往AGI方向的渐进步骤。
请写信给Steven Rosenbush,邮箱为[email protected],Isabelle Bousquette,邮箱为[email protected],以及Belle Lin,邮箱为[email protected]